#192 Calculations by hand, but in the compter, with Handcalcs
Python Bytes - A podcast by Michael Kennedy and Brian Okken - Lunedì

Categorie:
Sponsored by us! Support our work through:
- Our courses at Talk Python Training
- Test & Code Podcast
Brian #1: Building a self-updating profile README for GitHub
- Simon Willison, co-createor of Django
- “GitHub quietly released a new feature at some point in the past few days: profile READMEs. Create a repository with the same name as your GitHub account (in my case that’s github.com/simonw/simonw), add a
README.mdto it and GitHub will render the contents at the top of your personal profile page—for me that’s github.com/simonw” - Simon takes it one further, and uses GitHub actions to keep the README up to date.
- Uses Python to:
- Grab recent releases from certain GH repos using GH GraphQL API
- Links to blog entries using feedparser
- Retrieve latest links using SQL queries
Michael #2: Handcalcs
- Created by Connor Ferster
- In design engineering, you need to do lots of calculations and have those calculation sheets be kept as legal records as part of the project's design history.
- If they are not being done by hand, then often Excel is used but formatting calculations in Excel is time consuming and a maintenance nightmare.
- However, doing calculations in Jupyter is not any better even if you fill it up with print() statements and print to PDF: it just looks like a bunch of code output.
- Even proprietary software like MathCAD cannot render math as good as a hand calculation because it does not show the numerical substitution step. No software does
- Why handcalcs exists:
- Type the formula once into a Jupyter cell
- Have the calculation be rendered out as beautifully as though you had written it by hand.
Write your notebooks once, and use them for calculation again and again; the formula you write is the same as the representation of the formula.
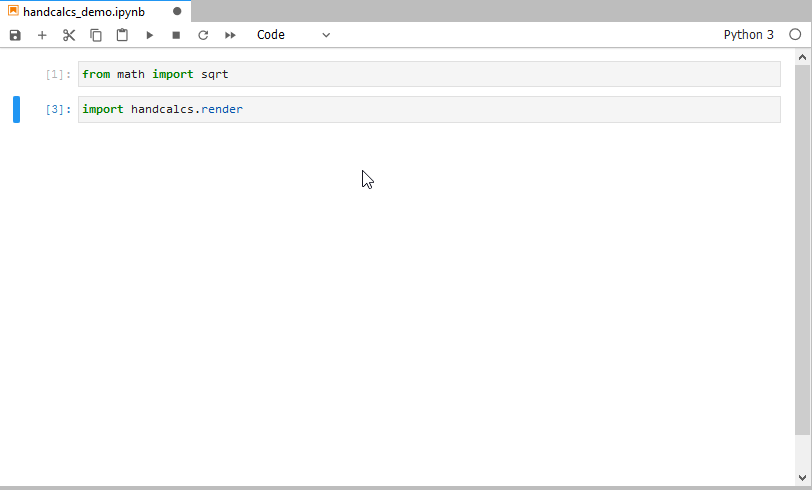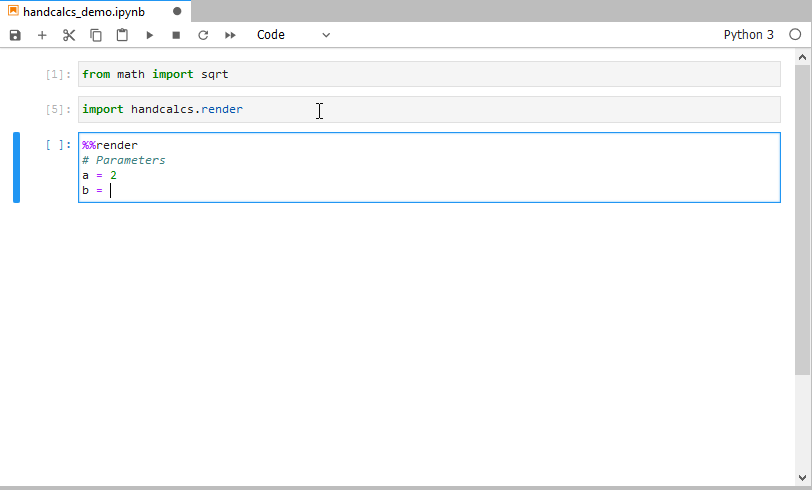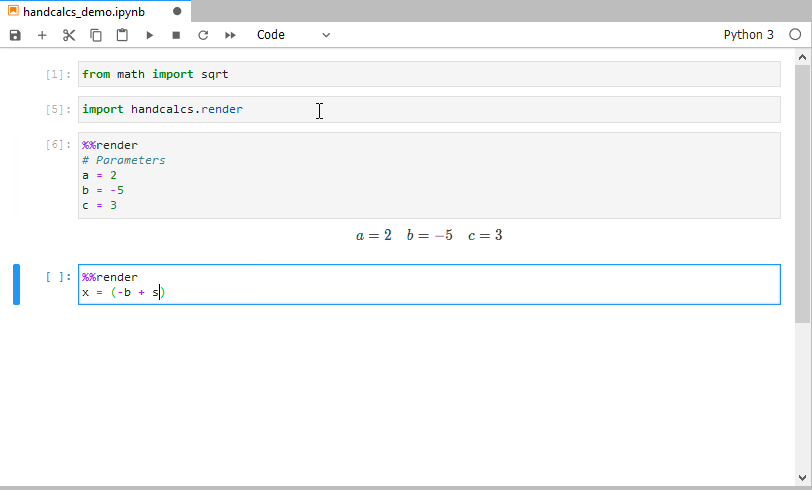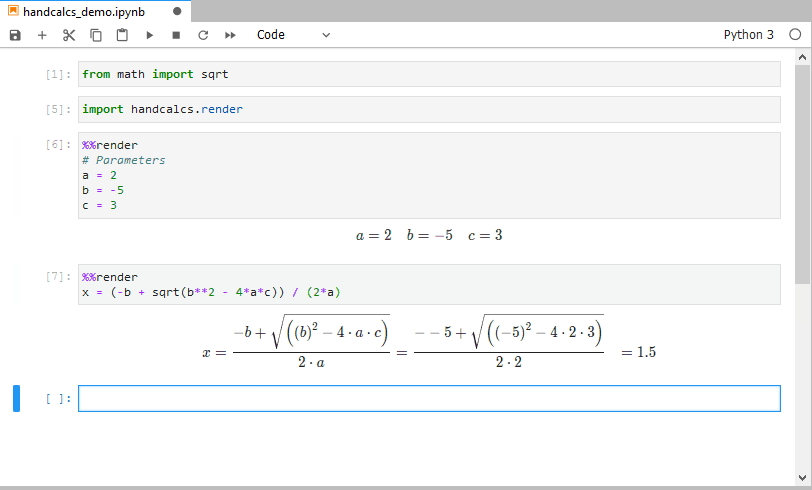
**Symbolic**The primary purpose ofhandcalcsis to render the full calculation with the numeric substitution. This allows for easy traceability and verification of the calculation.- However, there may be instances when it is preferred to simply display calculations symbolically. For example, you can use the
# Symbolictag to usehandcalcsas a fast way to render Latex equations symbolically. - Includes longhand vs. shorthand
- Use units (mm^3) for example.
Brian #3: The (non-)return of the Python print statement
- Article by Jake Edge
- Idea by Guido van Rossum to bring back the print statement.
- Short answer: not gonna happen
Michael #4: FastAPI for Flask Users
- Flask has become the de-facto choice for API development
- FastAPI that has been getting a lot of community traction lately
- Benefits
- Automatic data validation
- documentation generation
- baked-in best-practices such as pydantic schemas and python typing
- Running “Hello World” - super similar, but FastAPI is uvicorn out of the box
@app.get('/')vs@app.route('/')- FastAPI defers serving to a production-ready server called
uvicorn. - URL Variables:
- Flask
@app.route('/users/[HTML_REMOVED]')
def get_user_details(user_id):
- FastAPI
@app.get('/users/{user_id}')
def get_user_details(user_id: int):
- Query Strings
- Flask
@app.route('/search')
def search():
query = request.args.get('q')
- FastAPI
@app.get('/search')
def search(q: str):
- Taking inbound JSON request in FastAPI:
def lower_case(json_data: Dict) - Nice but if you define a
Sentencemodel via pydantic:
@app.post('/lowercase')
def lower_case(sentence: Sentence):
- Blueprints == Routers
- Automatic validation via pydantic
Brian #5: Tweet deleting with tweepy
- Chris Albon
- A useful and simple example of using tweepy to interact with Twitter
- Chris set up and shared a Python script that deletes tweets that are:
- older than 62 days
- have been liked by less than a 100 people
- haven’t been liked by yourself
Michael #6: Clinging to memory: how Python function calls can increase your memory usage
- by Itamar Turner-Trauring
- I had Itamar on Talk Python episode 274 to discuss FIL which was recently covered.
- This article basically uses FIL to explore patterns for lowering memory usage within the context of a function.
- With simple code like this, we expected 2GB of memory usage, but we saw 3GB: -
def process_data():
data = load_1GB_of_data()
return modify2(modify1(data))
- The problem is that first allocation: we don’t need it any more once
modify1()has created the modified version. But because of the local variabledatainprocess_data(), it is not freed from memory untilprocess_data()returns. - Solution #1: No local variable at all
return modify2(modify1(load_1GB_of_data()))
- Solution #2: Re-use the local variable
data = load_1GB_of_data()
data = modify1(data)
data = modify2(data)
return data
- Solution #3: Transfer object ownership
- See article
Extras:
Michael:
- Pickle Use Example via Adam.
- I once had to work on an API that spoke to a 3rd party service that was a little unusual. That communication to the 3rd party service was over a raw socket connection, so we were responsible for crafting specifically formatted byte arrays to send to them, and we'd get specifically formatted byte arrays back which we'd then have to parse out to determine what pieces of data were in the message. The other wrinkle: that service wasn't available 24/7 but only during limited specific testing periods which had to be negotiated days in advance.
- We instrumented the code with a feature flag to enable pickling all received messages from that 3rd party service.
- Python 3.8.4 is out
- I'm an Arctic Code Vault Contributor over at GitHub. You might be too.
Joke:

